Some large validators are voting one slot behind
The biggest validators are not the weird ones this time.
I expected the MaxEB performance chart to be boring: larger effective-balance validators are mostly run by serious operators, so they should miss less and vote cleaner. That was true for the 1024-2048 ETH bucket. It had the best liveness in the sample.
Then the bucket below it fell off a cliff.
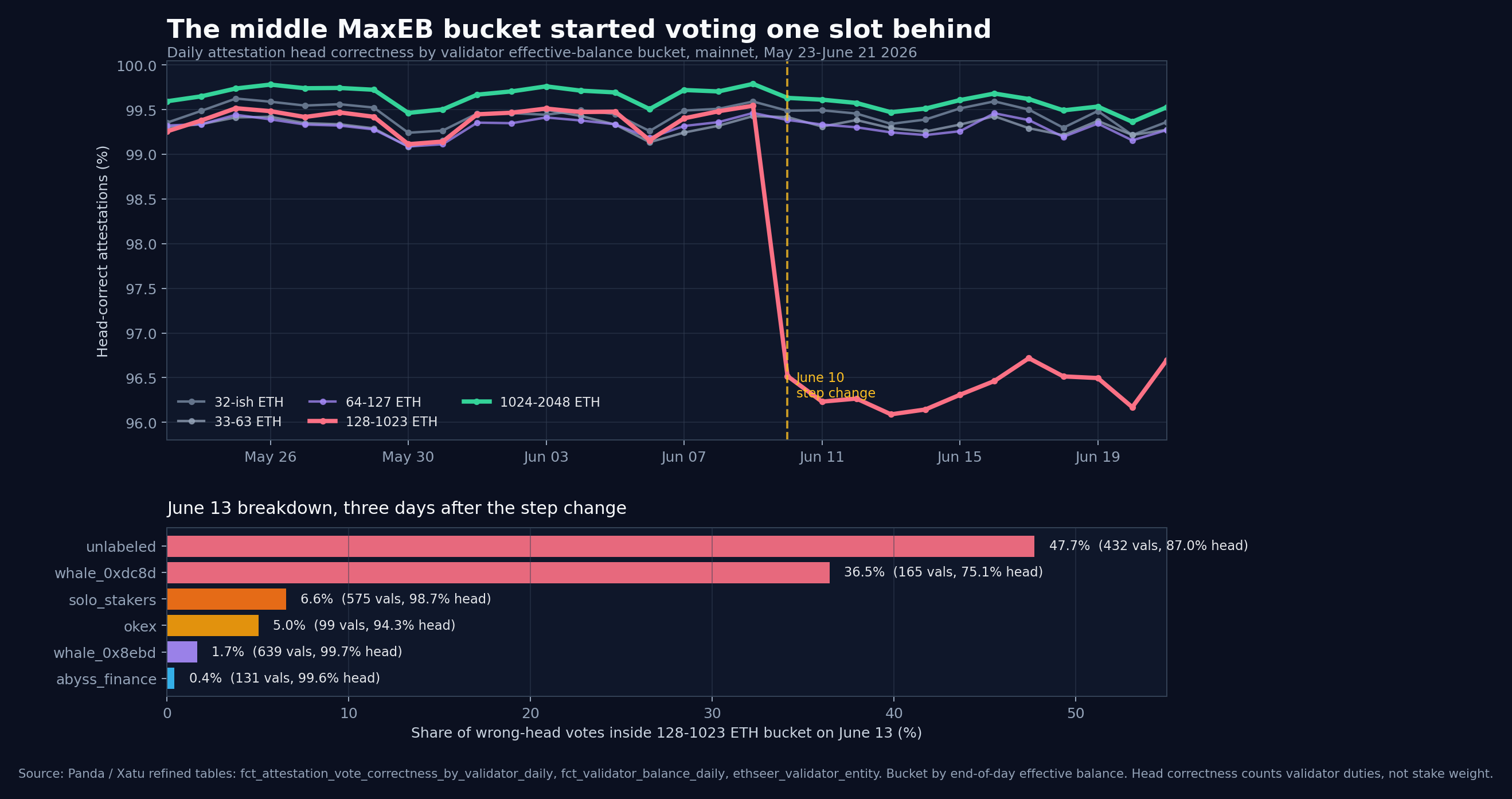
Across the 30 complete UTC days from May 23 through June 21, the 1024-2048 ETH validators were clean: 99.63% head-correct attestations, 0.038% missed duties.
The 128-1023 ETH bucket was the odd one. Before June 10, it was fine: 99.40% head-correct. From June 10 onward, it fell to 96.39%.
That is not a miss-rate story. Its post-change miss rate was still only 0.18%. These validators were attesting. They were just attesting to the wrong head.
The bucket query is basically this. I grouped validators by end-of-day effective balance, then summed daily attestation correctness by bucket:
WITH joined AS (
SELECT
a.day_start_date AS day,
multiIf(
b.effective_balance >= 1024000000000, '1024-2048 ETH',
b.effective_balance >= 128000000000, '128-1023 ETH',
b.effective_balance >= 64000000000, '64-127 ETH',
b.effective_balance >= 33000000000, '33-63 ETH',
'32-ish ETH'
) AS bucket,
a.total_duties,
a.attested_count,
a.missed_count,
a.head_correct_count,
a.target_correct_count,
a.source_correct_count
FROM mainnet.fct_attestation_vote_correctness_by_validator_daily AS a FINAL
INNER JOIN mainnet.fct_validator_balance_daily AS b FINAL
ON a.validator_index = b.validator_index
AND a.day_start_date = b.day_start_date
WHERE a.day_start_date >= toDate('2026-05-23')
AND a.day_start_date < toDate('2026-06-22')
AND b.status = 'active_ongoing'
)
SELECT
day,
bucket,
sum(total_duties) AS duties,
round(100 * sum(missed_count) / sum(total_duties), 4) AS miss_pct,
round(100 * sum(head_correct_count) / sum(attested_count), 4) AS head_correct_pct,
round(100 * sum(target_correct_count) / sum(attested_count), 4) AS target_correct_pct
FROM joined
GROUP BY day, bucket
ORDER BY day, bucket;
The source and target votes stayed boring. The target-correct rate for the 128-1023 ETH bucket over the whole window was 99.88%. So this was not validators falling off the chain or losing finality context.
It was a stale-head pattern.
I cross-checked June 13 against the per-validator canonical correctness table. In that one bucket, the table had 27,420 canonical rows where slot_distance = 1. In plain English: the validator attested to the previous slot's canonical block root instead of the current slot's head.
SELECT
status,
slot_distance,
count() AS rows
FROM mainnet.fct_attestation_correctness_by_validator_canonical FINAL
WHERE slot_start_date_time >= toDateTime('2026-06-13 00:00:00')
AND slot_start_date_time < toDateTime('2026-06-14 00:00:00')
AND attesting_validator_index IN (
/* validators with 128 <= effective_balance_eth < 1024 on 2026-06-13 */
)
GROUP BY status, slot_distance
ORDER BY status, slot_distance;
The concentration is the part that made me trust the finding. This was not the whole 128-1023 ETH bucket quietly getting worse.
On June 13, two cohorts produced most of the damage:
- an unlabeled group: 47.7% of wrong-head votes in the bucket, 86.97% head correctness
whale_0xdc8d: 36.5% of wrong-head votes, 75.11% head correctness- OKX added another 5.0%, at 94.27% head correctness
The worst individual validators were almost comical. They had zero missed duties, source votes correct, nearly all target votes correct, and 0% head correctness for the day. They were alive. They were punctual. They were just consistently one block behind.
The timing data gives the shape of the failure, but not the root cause.
For three representative validators that flipped on June 10, raw attestation first-seen moved earlier, not later. Median raw first-seen went from about 2.9s after slot start before June 10 to about 1.88s after June 10. Aggregate appearances also collapsed, from roughly 224 aggregates per day to about 20-25.
That is exactly the sort of shape I would expect from an attester firing before it has the current block, then voting the previous head. First-seen is observation time, not local signing time, so I would not call that a root cause. But it matches the slot-distance cross-check.
The important bit is narrower and, honestly, stranger:
Some mid-sized MaxEB validators did not go offline. They did not start missing source or target. They appear to have started attesting early enough that the head vote became stale.
The largest MaxEB validators were still the cleanest bucket in the chart. So this is not "large validators are bad." It is more annoying than that. One middle effective-balance cohort changed behavior on June 10, and because those validators carry hundreds of ETH each, a small index-count problem has a much bigger weight than it looks like from a validator-count dashboard.
Caveat: the chart counts validator duties, not stake-weighted votes. That is deliberate. I wanted to see the duty surface first. The stake-weighted version is the next question, and I would not assume it is kinder.