block_gossip has an eight-minute echo
block_gossip sounds like the clean block-arrival clock. Most of the time it is. Then Caplin shows up with canonical block roots arriving eight minutes after the slot started, which is not how blocks propagate on Ethereum unless something has gone very wrong.
Nothing went very wrong.
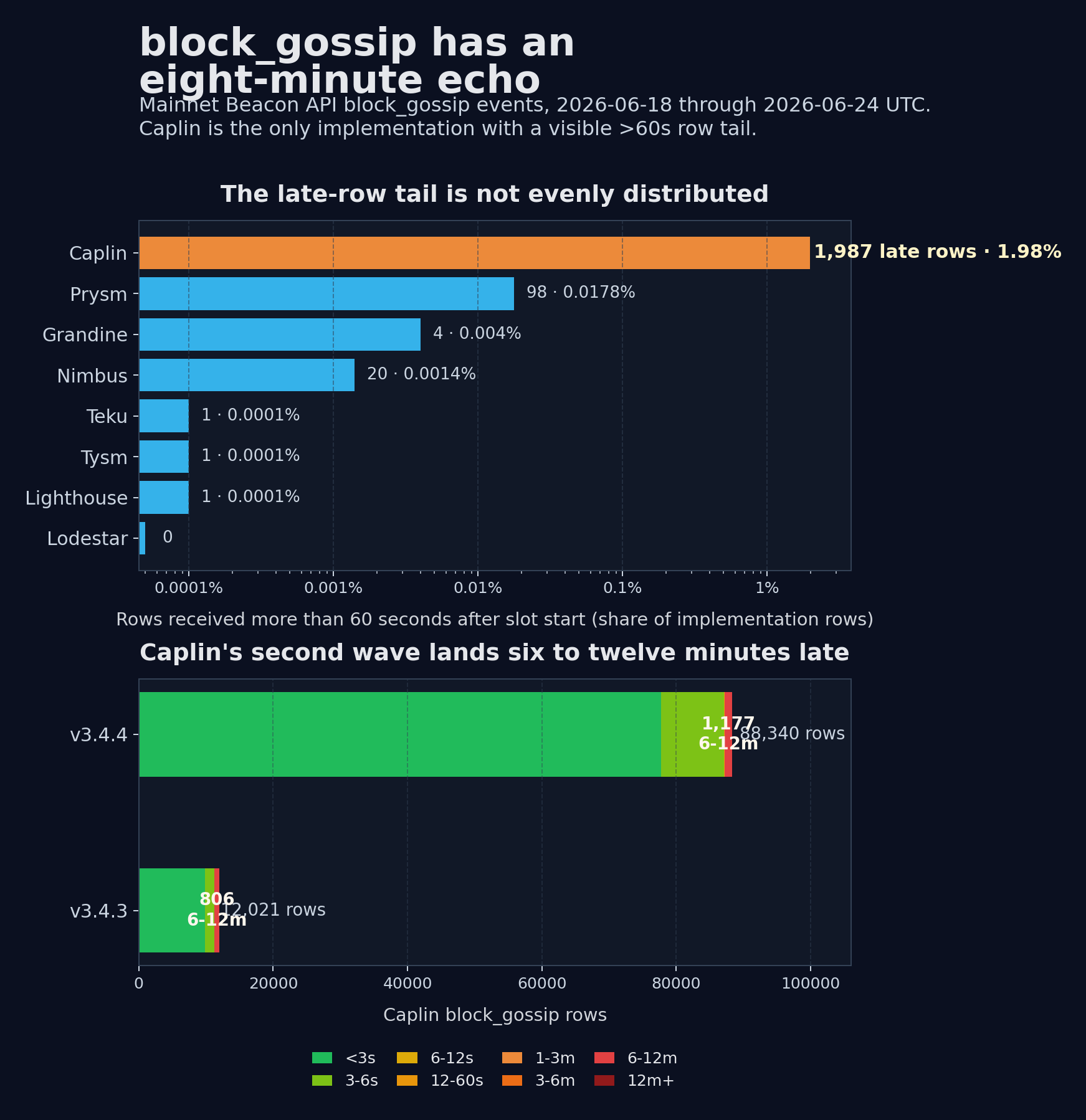
beacon_api_eth_v1_events_block_gossip, mainnet, June 18-24 2026 UTC. Late means propagation_slot_start_diff > 60000.The Beacon API spec describes block_gossip as the event for a block that passes validation rules for the beacon_block gossip topic. That makes it tempting to treat every row as a block propagation observation. I wanted to use the table that way because it has broad coverage: over June 18-24 UTC, every one of the 50,192 canonical mainnet blocks had at least one matching canonical block_gossip row, and the first matching row landed at 1.460s p50 / 3.118s p95 after slot start.
The first row is fine. The raw row distribution is not.
Here is the simple smell test:
SELECT
meta_consensus_implementation AS impl,
count() AS rows,
countIf(propagation_slot_start_diff > 60000) AS late60,
round(100 * late60 / rows, 4) AS pct_late60,
round(quantileExact(0.99)(propagation_slot_start_diff) / 1000, 3) AS p99_s,
round(max(propagation_slot_start_diff) / 1000, 3) AS max_s
FROM beacon_api_eth_v1_events_block_gossip
WHERE meta_network_name = 'mainnet'
AND slot_start_date_time >= toDateTime('2026-06-18 00:00:00')
AND slot_start_date_time < toDateTime('2026-06-25 00:00:00')
GROUP BY impl
ORDER BY late60 DESC;
That returned 6,496,584 block_gossip rows. Caplin had only 100,361 of them, but it had 1,987 rows more than 60 seconds after slot start. That is 1.98% of Caplin's rows. The next largest implementation tail was Prysm with 98 late rows out of 552,073 (0.0178%). Lodestar had none.
The Caplin late rows were not mildly late. Filtering only Caplin rows with propagation_slot_start_diff > 60000, the median was 487.034s after slot start and p95 was 642.457s. That is the eight-minute echo.
The important cross-check is whether those late rows are just orphan roots or bad joins. They mostly are not. I joined the late Caplin rows back to canonical beacon blocks by (slot, block_root):
WITH cb AS (
SELECT slot, block_root
FROM canonical_beacon_block
WHERE meta_network_name = 'mainnet'
AND slot_start_date_time >= toDateTime('2026-06-18 00:00:00')
AND slot_start_date_time < toDateTime('2026-06-25 00:00:00')
)
SELECT
bg.meta_consensus_version AS version,
count() AS late_rows,
uniqExact(bg.slot) AS late_slots,
countIf(bg.block = cb.block_root) AS canonical_late_rows,
countIf(bg.block != cb.block_root AND cb.block_root != '') AS noncanonical_late_rows,
countIf(cb.block_root = '') AS no_canonical_join,
round(quantileExact(0.5)(bg.propagation_slot_start_diff) / 1000, 3) AS late_p50_s
FROM beacon_api_eth_v1_events_block_gossip bg
GLOBAL ANY LEFT JOIN cb ON cb.slot = bg.slot
WHERE bg.meta_network_name = 'mainnet'
AND bg.slot_start_date_time >= toDateTime('2026-06-18 00:00:00')
AND bg.slot_start_date_time < toDateTime('2026-06-25 00:00:00')
AND bg.meta_consensus_implementation = 'caplin'
AND bg.propagation_slot_start_diff > 60000
GROUP BY version
ORDER BY version;
For v3.4.3-dirty linux, all 806 late rows matched canonical roots. For v3.4.4-dirty linux, 1,178 of 1,181 late rows matched canonical roots, with zero conflicting noncanonical roots and three rows where the canonical join found no row. So this is not just the orphan tail wearing a funny hat. It is mostly canonical blocks being surfaced again long after they mattered for propagation.
The shape also shows up inside Caplin itself. In the v3.4.4 sample, 1,090 slot/root pairs had at least one row after 60 seconds. 999 of those also had a timely Caplin row for the same slot/root. If you take the first Caplin block_gossip row per slot/root, v3.4.4 has a 3.574s p99. If you take the last row, p99 becomes 490.848s. Same table, same blocks, completely different story.
That is the trap. A raw p99 over rows says "Caplin block gossip is broken for minutes." A first-seen reduction says "Caplin usually saw the block on time, then a subset of observations echoed the same canonical root minutes later." Those are not the same claim.
I also checked the same implementation on the normal head eventstream. Caplin's head rows over the same week had zero rows after 60 seconds and p99 was 4.358s. The late-minute tail is specific to the block_gossip surface, not a general "Caplin was eight minutes behind the chain" story.
For now, the safe query shape is boring: group by slot, block, take min(propagation_slot_start_diff), and only then compare clients or join to other timing data. If the question is about duplicate/late eventstream behavior, keep the raw rows. If the question is block propagation, raw rows are the wrong denominator.
This is an observed Xatu eventstream surface, not a client market-share claim and not a full network census. It also does not say the chain gossiped a block eight minutes late.
The block was fine. The row was haunted.