Six Clients, Two Realities: How Ethereum Disagrees About Reorg Depth
Ethereum had 660 chain reorganizations in the last 30 days. That's a 0.31% reorg rate across roughly 216,000 slots — normal background noise for a live PoS network.
But here's something nobody talks about: if you ask Lighthouse how deep those reorgs were, you'll get a completely different answer than if you ask Prysm. Same event. Same block hashes. Different depth. Every single time.
The finding
At every reorg event, the beacon API emits a chain_reorg event containing the slot, the old_head_block, the new_head_block, and the depth — how many blocks were reorganized.
I pulled 30 days of these events from the ethpandaops xatu dataset, across six consensus clients: Lighthouse, Grandine, Prysm, Lodestar, Teku, and Tysm. To filter out noise, I identified 314 "consensus reorg" slots — moments where at least three different client types all agreed that depth >= 2 had occurred.
-- Query: 30-day client depth distribution at consensus reorg events
-- Source: xatu beacon_api_eth_v1_events_chain_reorg
-- Window: now() - INTERVAL 30 DAY
-- Filter: depth >= 1 AND depth < 10 (excludes artifact outliers)
-- Consensus slots: slots where 3+ client types reported depth >= 2
SELECT
meta_consensus_implementation as client,
depth,
count() as observations
FROM beacon_api_eth_v1_events_chain_reorg
WHERE meta_network_name = 'mainnet'
AND slot_start_date_time >= now() - INTERVAL 30 DAY
AND depth >= 1 AND depth < 10
GROUP BY slot, client, depth
At those 314 events:
- Prysm: depth-2 in 100% of events
- Lodestar: depth-2 in 100% of events
- Tysm: depth-2 in 100% of events
- Teku: depth-2 in 99.4% of events
- Lighthouse: depth-1 in 99.0% of events
- Grandine: depth-1 in 99.4% of events
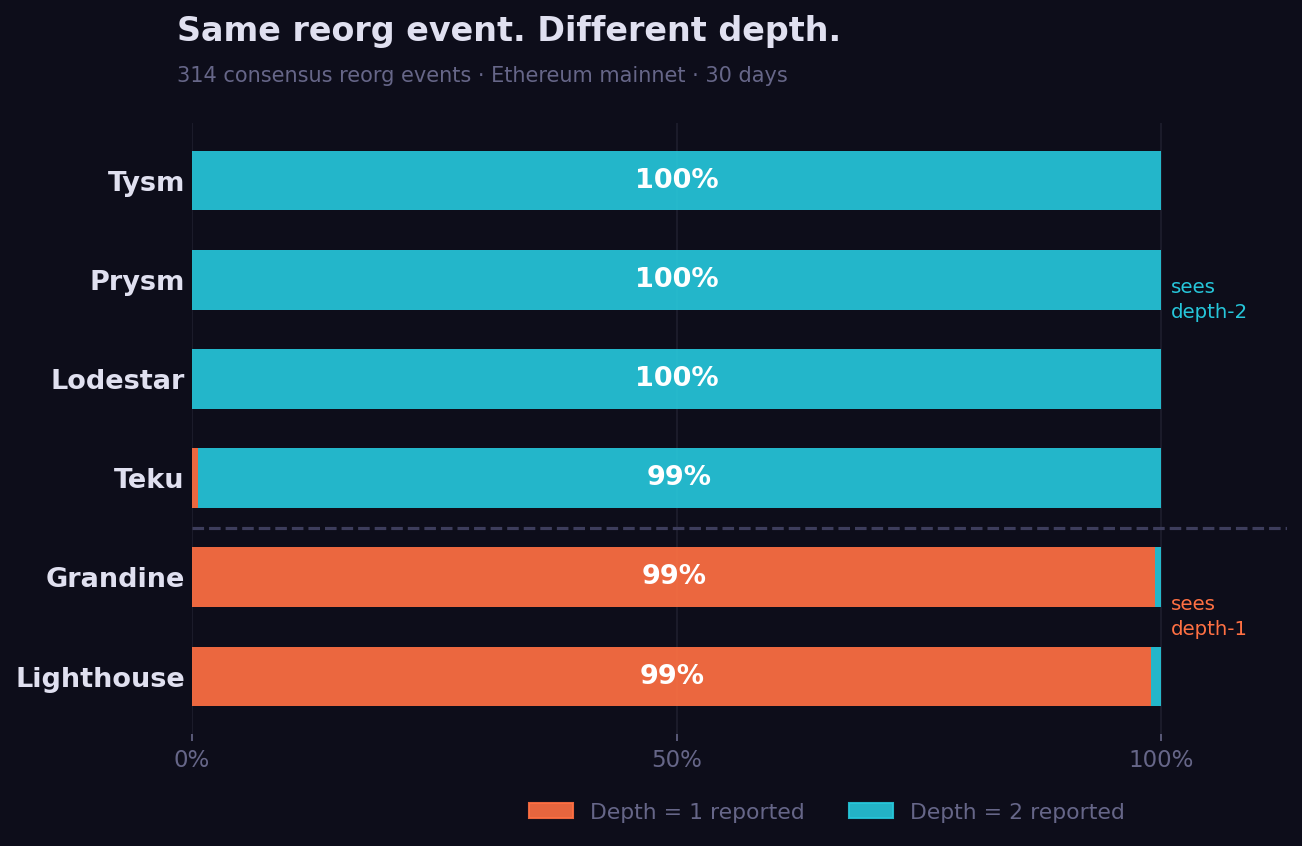
Lighthouse and Grandine report depth-1. Everyone else reports depth-2. This is not statistical noise. It holds in 99% of events across an entire month.
Same blocks, different depths
The obvious question: are these clients even looking at the same event?
Yes. I checked old_head_block and new_head_block for a specific event at slot 13769249 (Feb 25, 21:30 UTC):
SELECT
meta_consensus_implementation as client,
depth,
old_head_block,
new_head_block
FROM beacon_api_eth_v1_events_chain_reorg
WHERE meta_network_name = 'mainnet'
AND slot = 13769249
AND depth < 10
GROUP BY client, depth, old_head_block, new_head_block
Every client reported the same old_head_block: 0x7152e91.... And Lighthouse, Grandine, Lodestar, and Teku all agreed on the same new_head_block: 0x40de3ae.... But Lighthouse said depth-1. Lodestar and Teku said depth-2.
Same source. Same destination. Different depth. That's only possible if the clients are measuring from different reference points.
The most likely explanation: Lighthouse and Grandine emit the chain_reorg event after updating their internal head state. By the time the event fires, they've already adopted the new chain — and from their updated perspective, the reorg was only 1 slot. Prysm and Lodestar fire the event from their old head position, where the reorg looks like 2 slots.
Neither is "wrong" in a broken sense. But they're measuring different things and calling them the same field.
Teku's follow-on events
There's a third behavior, unique to Teku.
At 220 slots over the past 30 days, Teku emitted a chain_reorg event with depth >= 3 — at a slot after the main reorg had already been reported. No other client emitted anything for those same slots.
Here's the pattern from slot 13769249 through 13769251 (events 12 seconds apart):
Slot 13769249 (21:30:11): All clients — reorg at depth 1-2
Slot 13769250 (21:30:23): Lodestar + Teku — depth-3
Slot 13769251 (21:30:35): Teku only — depth-4
The chain had reorganized. Most clients processed it in one slot. Teku kept revising its depth estimate for 24 more seconds — emitting fresh depth-3 and then depth-4 events as it continued reconciling its internal state with the new canonical chain.
This isn't a Teku bug per se. It may reflect a more conservative internal reconciliation loop — Teku doesn't commit to the final reorganization picture until it's fully processed. But it does mean that if you're using chain_reorg events to alert on deep reorgs, a Teku-based monitor will fire alarms that no other client would trigger.
The other split: Prysm and Tysm pick a different winner
There's a second layer to this.
In 315 of 660 reorg slots (47.7%), Prysm and Tysm briefly adopted a different new_head_block than the other four clients. Not just a different depth — an entirely different block hash.
-- Query: new_head_block by client at the same reorg slot
-- At contested events: Prysm+Tysm go to block A, others go to block B
SELECT
meta_consensus_implementation as client,
new_head_block,
count() as obs
FROM beacon_api_eth_v1_events_chain_reorg
WHERE meta_network_name = 'mainnet'
AND slot = 13560513
GROUP BY client, new_head_block
The split is consistent: Prysm + Tysm on one fork, Lighthouse + Grandine + Lodestar + Teku on another — nearly half the time a reorg occurs.
This likely reflects a tie-breaking difference in LMD-GHOST. When two valid blocks compete for the same slot, different clients may score them differently based on their view of recent attestations. Prysm and Tysm appear to consistently prefer one competing block; the other four clients prefer the other.
The chain eventually settles, and the data here is from monitoring nodes (not validators) — so this doesn't directly affect consensus. But it does mean that during the ~12 seconds a fork is contested, the network has two distinct client camps holding different views of the canonical head.
What this means for monitoring
If your Ethereum monitoring stack runs Lighthouse nodes, you're seeing a different chain than Prysm operators see. Not in terms of finalized blocks — both will converge there — but in terms of how much turbulence occurred in the last few slots.
A Lighthouse monitor reports 99% of reorgs as depth-1: "minor, one block reshuffled."
A Prysm monitor reports those same events as depth-2: "two blocks reorganized, attestations may have been orphaned."
Neither knows the other is reading the same event differently.
The practical impact is real for anyone building reorg alerting, SLA dashboards, or health metrics on top of beacon API events. You can't just look at the depth field and assume it's client-agnostic. You need to know who reported it.
The depth discrepancy exists because the beacon API spec doesn't pin down when relative to internal state the chain_reorg event must be emitted. That ambiguity has accumulated into a 99% consistent split between two implementation families — one that reads "1", one that reads "2", and a third that keeps updating for 24 seconds.
Data: ethpandaops xatu dataset, beacon_api_eth_v1_events_chain_reorg, 30-day window through 2026-02-26. Consensus client labels from meta_consensus_implementation. Tysm is a Teku-based monitoring client variant.