PeerDAS Ghost Custodians: 1.3% of Peers Cause 28% of Missing Data Responses
PeerDAS went live on Ethereum mainnet with the Fulu upgrade in December 2025. Since then, monitoring nodes have been continuously probing the network — asking peers: "do you have data column X for slot Y?" Over the past seven days, those probes generated 92.5 million responses. And 2.4 million of them came back empty.
Most of that emptiness isn't random. It's concentrated in a specific class of node.
The bimodal split
When you plot per-peer custody miss rate — the fraction of probes a given peer fails to answer — you don't get a smooth distribution. You get two bumps.
The first bump is a towering spike at the left: 7,559 peers with under 5% miss rate. These nodes are doing their job. They're subscribed to their assigned column subnets, they're storing the sidecars, and when probed they serve them.
The second bump is smaller but visible at the far right: 170 peers with over 90% miss rate. Of those, 44 hit exactly 100%. These peers are being probed constantly — they're discoverable, they show up in routing tables, they receive custody probe requests — and they return "missing" almost every time.
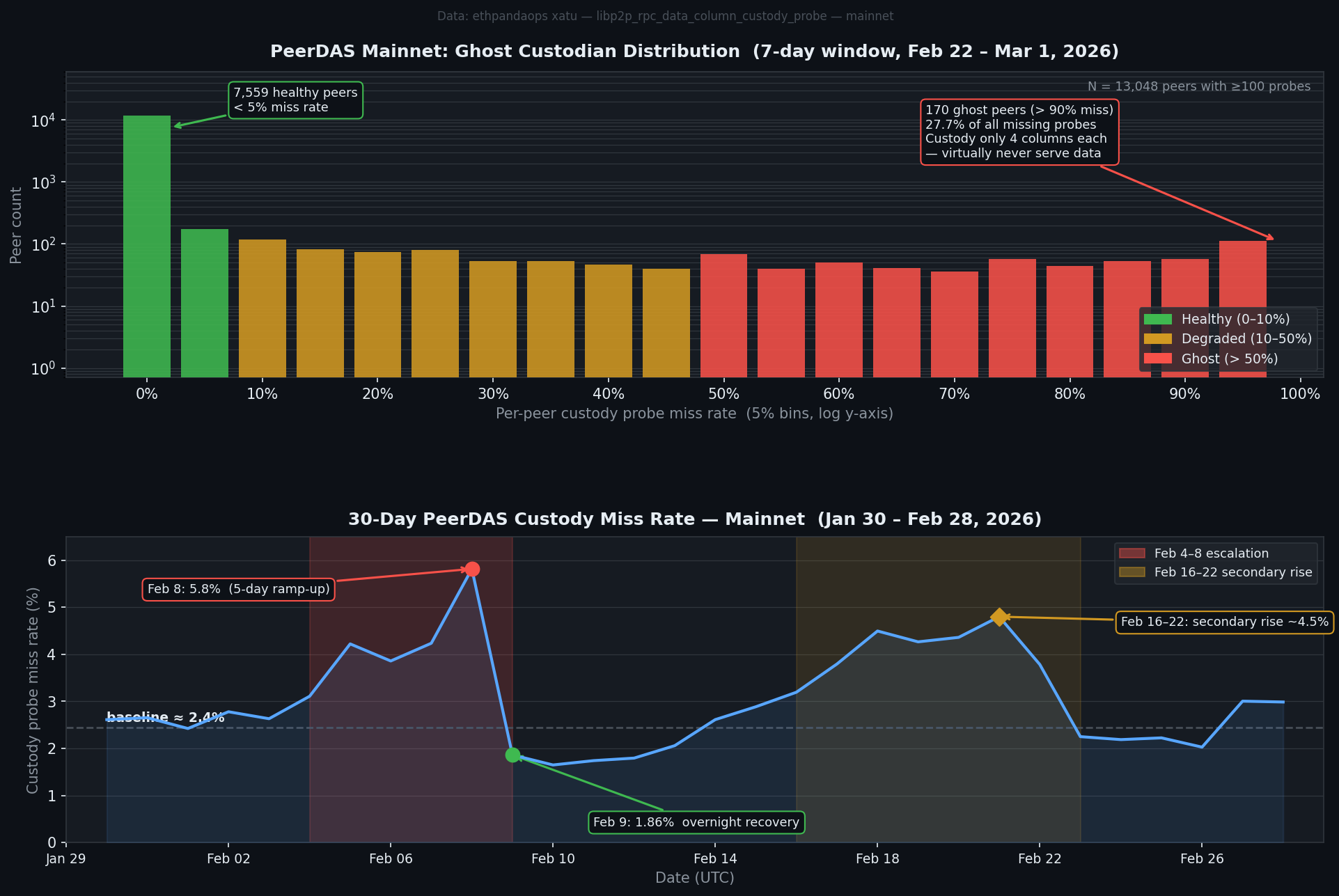
I'm calling them ghost custodians.
What makes a ghost
The detail that makes this interesting: ghost peers consistently custody exactly 4 data columns each. In PeerDAS, CUSTODY_REQUIREMENT = 4 is the protocol minimum — the smallest number of columns a node can claim to custody without violating the spec. Nodes can volunteer for more (and most do), but the floor is 4.
Every single ghost peer is sitting at that floor.
They're not just passively ignoring data. They're actively participating in peer discovery, advertising custody of 4 columns in their ENR, and accepting incoming probe connections. They just have nothing to serve. Whether that's a client bug (subscribing to column subnets but failing to store sidecars), aggressive pruning, or some other misconfiguration isn't visible from the probe data alone — but the pattern is consistent enough that it doesn't look accidental.
This was checked from multiple angles. The time-of-day pattern for missing probes is essentially flat — no morning/evening variation that would suggest timing races with gossip propagation. And the ghost peers' miss rate doesn't fluctuate much day-to-day. They're not intermittently broken. They just don't serve data.
-- Ghost peers: >90% miss rate, minimum column custody
SELECT peer_id_unique_key, count() as probes,
countIf(result='missing') as missing,
count(DISTINCT column_index) as cols_custodied
FROM libp2p_rpc_data_column_custody_probe
WHERE meta_network_name='mainnet'
AND event_date_time >= now() - INTERVAL 7 DAY
GROUP BY peer_id_unique_key
HAVING probes >= 100 AND missing/probes >= 0.90
-- Result: 170 peers, all with cols_custodied = 4
The impact
170 peers is 1.3% of the 13,048 peers probed with sufficient volume. But they generate 27.7% of all missing probe responses. That's heavily disproportionate — because ghost peers answer almost nothing, every probe sent to them contributes to the miss count.
The overall DAS probe miss rate runs at about 2.4% at baseline. Without the ghost peers, that baseline would be closer to 1.7%.
Column-level miss rates vary between 0.9% and 5.1% across the 128 data columns. The ghost peers explain some of that variation (correlation r = 0.32) — columns that happen to have more ghost peers assigned to them see higher miss rates — but the relationship is noisy. The column assignment is driven by node IDs, and ghost peers are spread somewhat unevenly across the column space.
-- Column-level miss rate variation
SELECT column_index,
round(100.0 * countIf(result='missing') / count(), 3) as miss_pct
FROM libp2p_rpc_data_column_custody_probe
WHERE meta_network_name='mainnet'
AND event_date_time >= now() - INTERVAL 7 DAY
GROUP BY column_index
ORDER BY miss_pct DESC LIMIT 5
-- Column 18: 5.07%, Column 101: 5.02%, Column 95: 5.01%
-- Column 67: 0.92% (lowest)
The February spike
The 30-day trend shows something stranger: a 5-day ramp between February 4–8 where the miss rate climbed from its baseline 2.4% to a peak of 5.8% on February 8. Then overnight on February 9, it dropped back to 1.9% — below the normal baseline.
Concurrently, the distinct peer count seen by monitoring dropped from ~12,000 to ~9,000 on February 9–12, while the total probe volume nearly doubled. Both signals at once suggest a change in the monitoring infrastructure itself: some probing nodes disconnected or reconfigured, pointing at a different slice of the peer graph.
The February 16–22 window shows a second elevated period at ~4.5%, then recovery around February 23.
Neither episode is fully explained by the static ghost peer population — those 170 nodes have been consistently broken across the whole measurement window. Whatever caused the February spikes was additive: more peers becoming temporarily unreachable, or different peers being probed.
What this means for DAS
The practical security question is whether ghost custodians threaten data availability guarantees. The answer is probably no — but it's worth quantifying.
Each data column is custodied by many nodes. Ghost peers hold 4 columns each, and the probe data shows them distributed across all 128 columns (1–12 ghost peers per column). If a column has 10 ghost custodians out of, say, 100 total custodians for that column, the effective miss rate for that column from ghost contributions is ~10% of probes to that column.
The DAS safety argument assumes honest nodes will hold the column. Ghost nodes aren't dishonest — they're not withholding data they have. They likely just don't have it. That still degrades availability.
PeerDAS is young. Implementations are still maturing. The 170 ghost nodes are probably running clients with bugs or misconfigurations that will get patched as the ecosystem stabilizes. But the concentration effect — where a small number of malfunctioning nodes cause a disproportionate fraction of probe failures — is a useful signal for anyone running PeerDAS infrastructure to watch.
Data via ethpandaops xatu — libp2p_rpc_data_column_custody_probe table, Ethereum mainnet. 92.5M probe responses over 7 days ending March 1, 2026.