The Blob Blindspot: Half of Nethermind Validators Still Can't Serve Blobs
One month after Pectra went live, roughly 44% of all Nethermind validator nodes are rejecting a blob retrieval call that was introduced in that very fork. Every other major execution client has mostly fixed this. Nethermind hasn't moved.
This is the data on what's happening, why it matters, and where the fault line sits.
What engine_getBlobsV2 does
Pectra (activated January 25, 2026) added a new Engine API call: engine_getBlobsV2. The idea is simple — when a consensus client receives a new block containing blob commitments, it asks its execution client: "do you have these blobs in your local cache?" The EL, which participates in the blob P2P network independently, should already have them. The CL can then verify blob availability without touching the P2P layer itself.
If the EL says "I don't have it" — or worse, "I don't support this call" — the CL has to fall back and fetch all blobs itself from peers. With typical blocks carrying 5–6 blobs (post-Pectra target), that's a non-trivial fallback.
The UNSUPPORTED status code specifically means the EL doesn't implement the method at all. It returns in ~1 ms with zero blobs. That's not a cache miss — it's a blank stare.
Nethermind: stuck at 44% since day one
The ethpandaops infrastructure has been monitoring engine_getBlobsV2 calls since shortly after Pectra launched. The pattern for Nethermind validator (non-builder) nodes is stark.
Query: fct_engine_get_blobs_by_el_client
Filter: node_class = '', mainnet, Jan 25 – Feb 25, 2026
Group: day, meta_execution_implementation, status
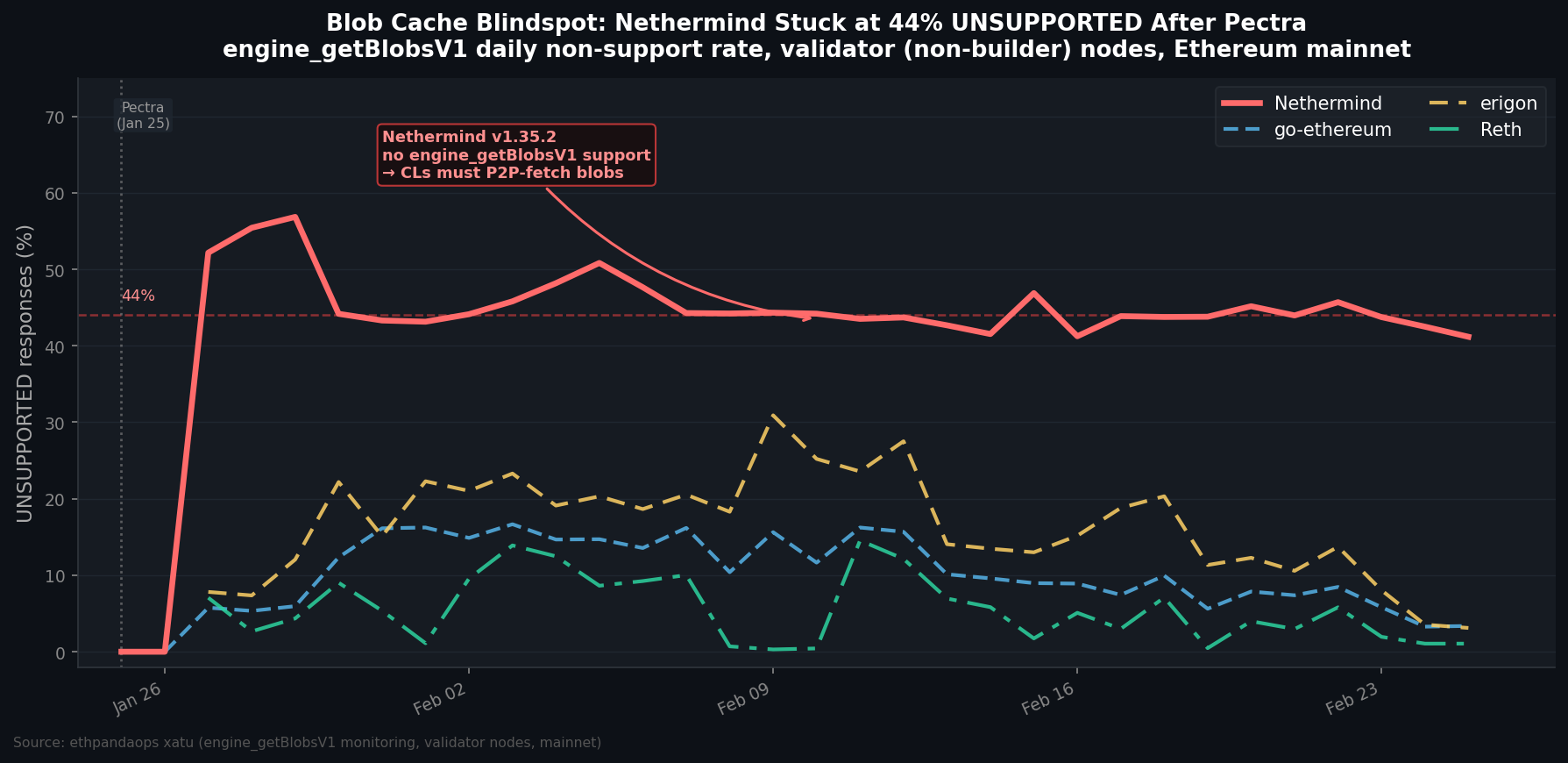
On January 27 — the first full day of monitoring data — Nethermind regular validator nodes showed a 52% UNSUPPORTED rate. One month later, it's still 41%.
Every other EL client has converged toward near-zero:
- Reth started at 7–14% and is now at ~1%
- go-ethereum dropped from ~16% to ~3%
- Erigon declined from ~22% to ~3%
Nethermind hasn't moved.
The culprit: one specific version
Drilling into the raw execution_engine_get_blobs table reveals the version breakdown clearly.
Query: execution_engine_get_blobs
Filter: meta_execution_implementation = 'Nethermind', mainnet, 7d
Group: meta_execution_version_minor, status
| Version | SUCCESS calls | UNSUPPORTED calls | UNSUPPORTED rate |
|---|---|---|---|
| v1.37.x | 52,399 | 1,530 | 3% |
| v1.35.x | 41,625 | 107,294 | 72% |
Nethermind v1.37.x handles blob requests just fine. Nethermind v1.35.2 — specifically the build tagged 1.35.2+faa9b9e6 — is responsible for 107,000+ UNSUPPORTED responses in the past week alone. That single build accounts for the majority of Nethermind's blindspot.
The version gap spans at least one minor release cycle. v1.35.x didn't ship engine_getBlobsV2 support; v1.37.x did. And a large cohort of validator operators hasn't crossed that boundary in the month since Pectra launched.
Builders know — validators don't
There's a telling split within Nethermind's own ecosystem. The same dataset, filtered by node_class:
Query: fct_engine_get_blobs_by_el_client
Filter: mainnet, 7d, meta_execution_implementation = 'Nethermind'
Group: node_class, status
| Node type | UNSUPPORTED rate |
|---|---|
Validator nodes (node_class = '') | 44% |
Block builder nodes (node_class = 'eip7870-block-builder') | 6% |
Builder operators — the teams running MEV infrastructure 24/7 — are almost entirely on v1.37.x. They update constantly because being on stale software costs them money.
Validator operators don't have the same forcing function. Many are running solo stakers or smaller services on set-and-forget configurations. A 30-day version gap is normal for that population. The problem is that Pectra introduced a new requirement they don't know they're failing.
The practical cost
When a CL is paired with a v1.35.2 Nethermind, every blob-bearing block triggers the following sequence:
- CL sends
engine_getBlobsV2→ getsUNSUPPORTEDin 1 ms - CL falls back to P2P blob fetching — independently requesting each blob hash from its gossip peers
- If blobs are already propagated (usually true), the fetch completes in tens to hundreds of milliseconds
- If the network is under load, fetches can take longer
Most of the time this is a performance cost, not a correctness failure. The CL will eventually get the blobs. But timing matters in Ethereum PoS — attestations must be published within about 4 seconds of slot start, and block processing competes for that same window. Consistently slow blob resolution means consistently slower block processing, which means validators paired with v1.35.2 Nethermind are running slightly more exposed to attestation timing pressure.
At scale, 44% of the Nethermind validator population is a meaningful fraction of the network. It's not catastrophic, but it's a quiet drag that's been running since day one of Pectra.
What to do
If you're running Nethermind as your execution client, check your version:
# Nethermind HTTP API
curl -s -X POST http://localhost:8545 \
-H 'Content-Type: application/json' \
-d '{"jsonrpc":"2.0","method":"web3_clientVersion","params":[],"id":1}'
If you see Nethermind/v1.35.x, upgrade. The v1.37.x releases include engine_getBlobsV2 support and the UNSUPPORTED rate for those builds is ~3%.
The broader point: Pectra changed more than just blob limits. It added new Engine API surface that older EL versions simply don't implement. Validators who updated their node software before the fork might have been on a version that predated those additions. One month in, that's still showing up clearly in the data.
Data source: ethpandaops xatu, execution_engine_get_blobs table (raw) and mainnet.fct_engine_get_blobs_by_el_client (CBT), mainnet, January 25 – February 25, 2026. Validator nodes only (node_class = ''). Builder nodes excluded.