Your Ethereum Client Is Burning Through Your SSD
Ethereum has five execution clients and six consensus clients. Everyone has opinions about which is fastest — but almost nobody talks about what they do to your disk.
The short answer: your choice of client stack determines whether your SSD lasts four years or forty.
The data here comes from ethpandaops' monitoring nodes — a fleet of machines running every client combination, continuously observed over seven days ending February 28, 2026. These are mainnet nodes, not testnets. The disk I/O figures come directly from /proc/<pid>/io, the same counters used by every Linux performance tool.
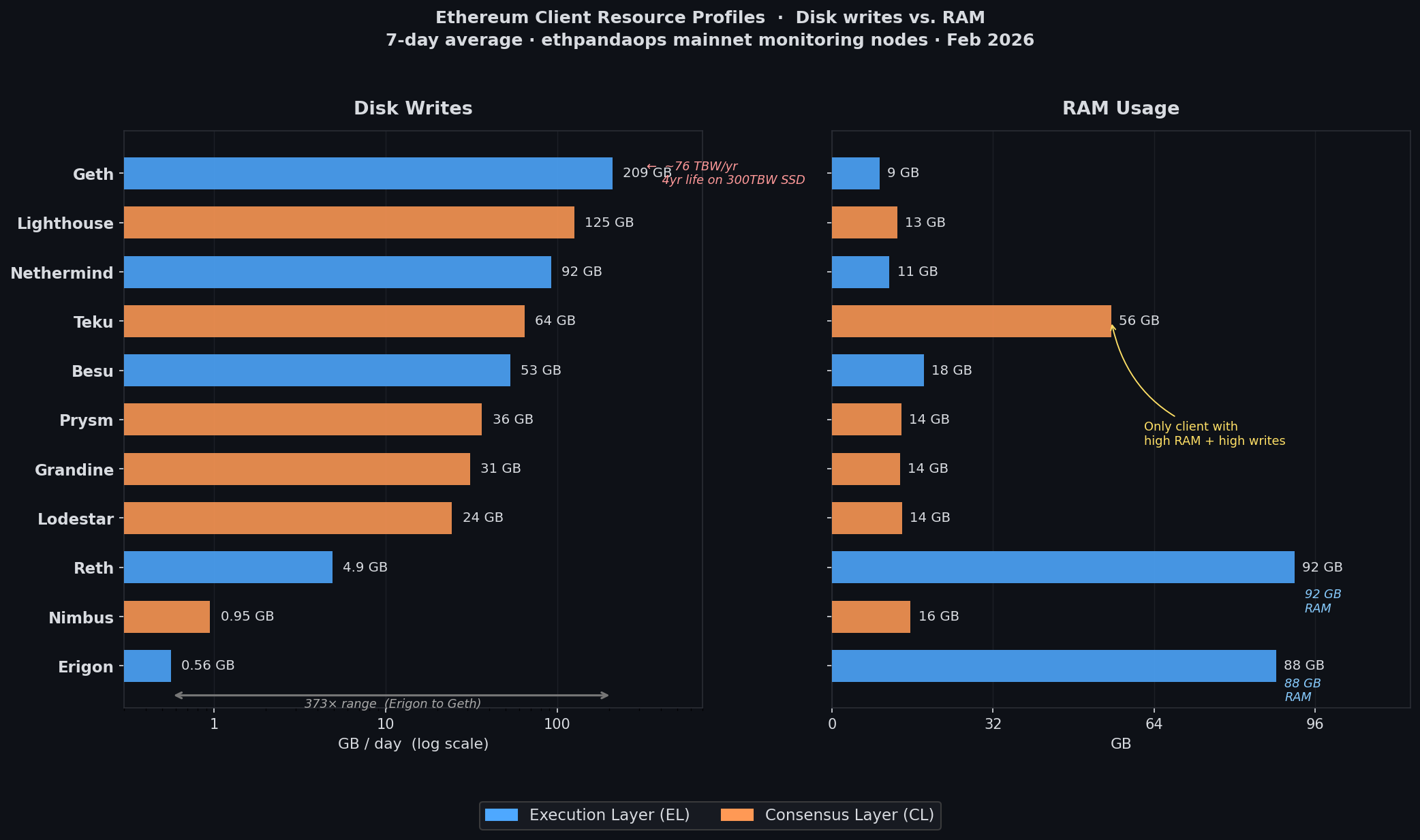
Geth writes 209 GB to disk every day. Erigon writes 0.56 GB. That's a 373× gap between two clients doing the same job on the same network.
-- 7-day average disk write I/O per execution client (mainnet monitoring nodes)
SELECT
client_type,
round(avg(io_bytes) * 7200 / 1e9, 2) as write_gb_per_day,
round(avg(vm_rss_bytes) / 1e9, 1) as ram_gb
FROM mainnet.fct_node_disk_io_by_process d
JOIN mainnet.fct_node_memory_usage_by_process m
USING (meta_client_name, wallclock_slot)
WHERE d.meta_network_name = 'mainnet'
AND d.meta_client_name LIKE '%mainnet%'
AND d.wallclock_slot_start_date_time >= now() - INTERVAL 7 DAY
AND d.rw = 'write'
AND d.client_type IN ('geth','reth','nethermind','erigon','besu')
GROUP BY client_type
ORDER BY write_gb_per_day DESC
| Client | Writes/day | RAM |
|---|---|---|
| Geth | 209 GB | 9 GB |
| Nethermind | 92 GB | 11 GB |
| Besu | 53 GB | 18 GB |
| Reth | 5 GB | 92 GB |
| Erigon | 0.56 GB | 88 GB |
The pattern is immediate. Geth and Nethermind keep RAM low and write constantly. Reth and Erigon load ~90 GB of database into virtual memory and barely touch the disk. Trading 80 GB of RAM for 200 GB/day of write I/O is a real, measurable architectural choice — not a marketing claim.
For SSD endurance: Geth at 209 GB/day is approximately 76 TBW per year. A 1 TB consumer SSD with 300 TBW endurance rating would reach end-of-life in under four years. A prosumer Samsung 870 EVO 2TB (1,200 TBW) would last about fifteen years. The concern isn't theoretical — it's the difference between replacing your SSD once and never touching it.
The architecture explains everything. Geth uses LevelDB with frequent compaction cycles. Every block commits state changes through multiple LevelDB levels, and compaction periodically rewrites data — write amplification compounds quickly. Nine monitoring nodes across different CL pairings all show the same pattern: 90 to 430 GB/day depending on configuration, with an average of 209 GB.
Erigon uses MDBX in append-only mode. Writes are sequential and minimal; reads come from disk when the mapped region isn't warm in page cache. This is why Erigon reads 2.5 GB/day from disk while writing almost nothing — it's reading state that wasn't hot enough to stay resident, rather than writing compaction output.
Reth uses its own MDBX-derived storage. The result is similar to Erigon — 5 GB/day writes — but Reth maps even more state into memory (92 GB vs 88 GB), which likely explains its slightly higher write rate. Both are dramatically more storage-efficient than Geth or Nethermind regardless.
The consensus layer is a less obvious story. Lighthouse — generally considered one of the leaner CL clients — writes 125 GB/day. That's more than Nethermind. More than Besu. More than any EL client except Geth.
-- CL clients, same query
SELECT client_type, write_gb_per_day, ram_gb
-- Lighthouse: 125 GB writes, 13 GB RAM
-- Teku: 64 GB writes, 56 GB RAM
-- Prysm: 36 GB writes, 14 GB RAM
-- Grandine: 31 GB writes, 14 GB RAM
-- Lodestar: 24 GB writes, 14 GB RAM
-- Nimbus: 1 GB writes, 16 GB RAM
Lighthouse's write intensity likely comes from its historical attestation and block archive storage. The database grows as the chain grows, and Lighthouse keeps writing in large sequential batches.
Nimbus is the inverse: 0.95 GB/day in writes, 55.6 GB in reads. The same memory-mapped pattern as Erigon, applied to the consensus layer. Nimbus reads from its SQLite database but rarely flushes. On constrained hardware — Raspberry Pi, NUC, anything with a small but fast SSD — Nimbus and Erigon is probably the right pairing for SSD longevity reasons alone.
Teku is the outlier no other client matches: 55 GB of RAM and 64 GB/day of writes. Most clients make a tradeoff in one direction. Teku makes neither — it's the resource-heaviest CL client by RAM, and second-heaviest by disk writes.
One specific event stands out in the data. Besu's disk write rate collapsed from 388 GB/day on February 19th to 58 GB/day on February 22nd — a 6× reduction in 72 hours.
-- Besu daily write I/O over 20 days
SELECT toDate(wallclock_slot_start_date_time) as day,
round(avg(io_bytes) * 7200 / 1e9, 2) as write_gb_per_day
FROM mainnet.fct_node_disk_io_by_process
WHERE client_type = 'besu' AND rw = 'write'
AND wallclock_slot_start_date_time >= now() - INTERVAL 20 DAY
GROUP BY day ORDER BY day
-- Feb 11: 416 GB → Feb 18: 338 GB → Feb 21: 284 GB → Feb 22: 58 GB → Feb 28: 22 GB
This is an update event. The monitoring nodes received a new Besu version around February 21–22, and something in that release dramatically cut write amplification. The trend has continued downward since — Besu is now writing less than Geth per day, reversed from the opposite position it held three weeks ago.
No announcement was flagged on this specifically, but the data is unambiguous. A full month of 300–400 GB/day suddenly became 22 GB/day within a week.
The practical takeaway depends on your hardware. If you're running a validator on a desktop with a mid-range SSD, Geth + Lighthouse is probably the worst combination for disk longevity. Reth or Erigon + Nimbus is the best. The performance characteristics from engine_newPayload benchmarks might point one direction; the disk endurance picture points another.
None of this means Geth is bad — it's been reliable, well-tested, and the dominant EL client for years. But "reliable" and "easy on storage" aren't the same thing. The numbers exist, and they're measurable. Now they're measured.