p2porg publishes 96% of its blocks after 3 seconds. Its Lido validators publish on time.
There's a 3-second cliff in Ethereum's attestation system. Blocks that arrive after it — when validators have already started forming their head votes — cause measurable drops in head accuracy. The earlier post established that with 50,000 slots of data.
What it didn't answer: who's responsible?
The data to answer that is in two tables: libp2p_gossipsub_beacon_block in Xatu gives the first-seen gossip time for every block; mainnet.fct_block_proposer_entity in the CBT cluster maps each slot to a labelled staking entity. Joining them over seven days produces a timing game scorecard per operator.
-- Block first-seen: proxy for publication time
SELECT slot, min(propagation_slot_start_diff) as first_seen_ms
FROM libp2p_gossipsub_beacon_block
WHERE meta_network_name = 'mainnet'
AND slot_start_date_time >= now() - INTERVAL 7 DAY
AND propagation_slot_start_diff BETWEEN 0 AND 12000
GROUP BY slot
-- Entity per slot
SELECT slot, entity
FROM mainnet.fct_block_proposer_entity FINAL
WHERE slot_start_date_time >= now() - INTERVAL 7 DAY
The join covers 45,401 slots with entity labels. A block is "timing game" if its gossip arrival is more than 3 seconds after slot start — the point where head vote accuracy starts collapsing. Here's what the scorecard looks like:
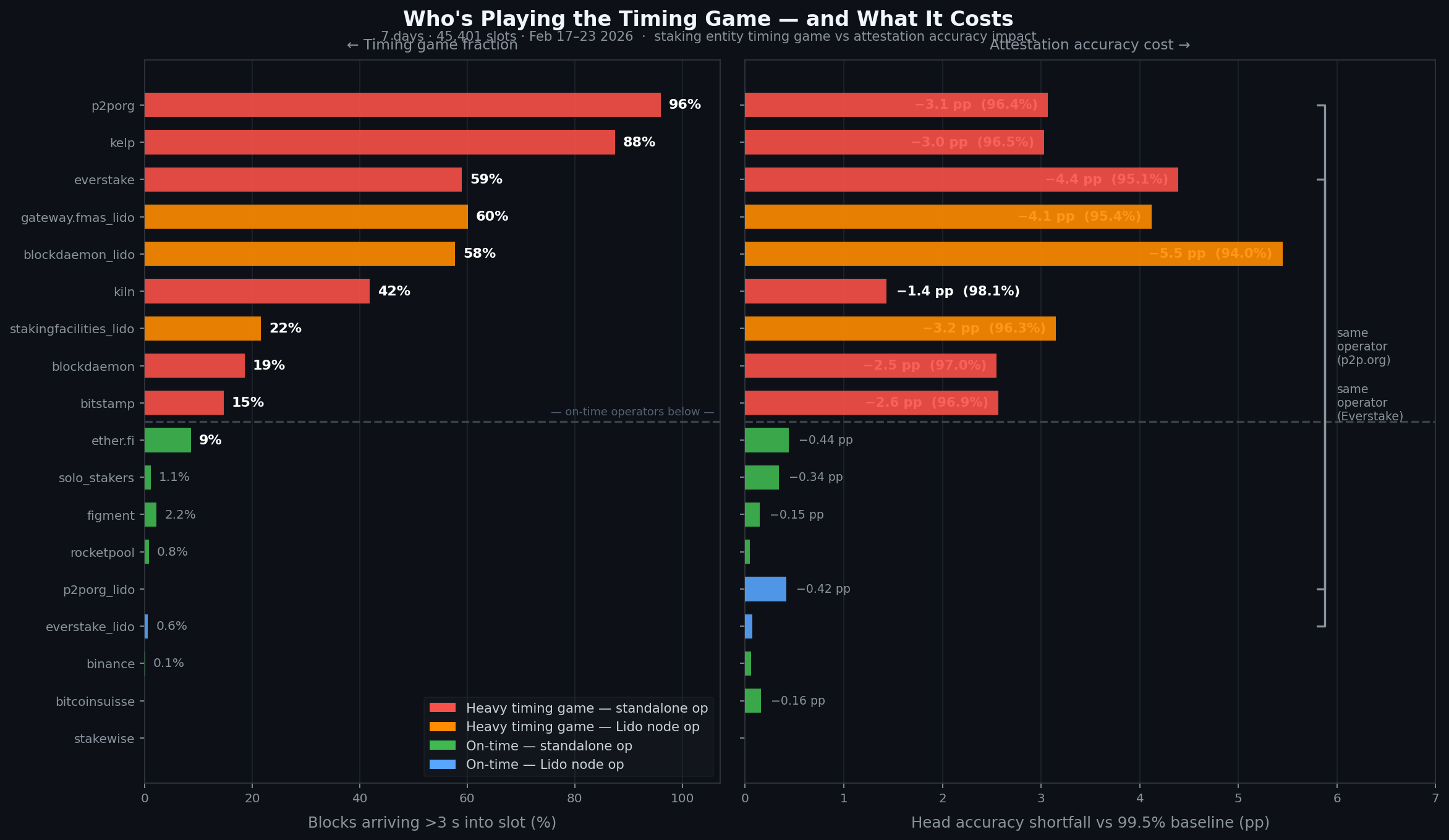
The top of the chart is dominated by a handful of operators. p2porg publishes 96% of its blocks after 3 seconds, every single day for seven days running. Not a network outage. Not a temporary misconfiguration. A consistent, stable pattern. Their median first-seen time is 3094ms — the block reliably arrives three seconds into the slot.
Kelp (a liquid restaking platform on EigenLayer) is at 87.5%. Everstake's standalone operation is at 59%. Gateway FMAS and Blockdaemon's Lido-operated validators both sit in the 57–60% range. Kiln is at 42%.
The head accuracy numbers follow directly:
| Entity | Timing game blocks | Avg head accuracy |
|---|---|---|
| blockdaemon_lido | 57.7% | 94.05% |
| everstake | 59.0% | 95.11% |
| gateway.fmas_lido | 60.1% | 95.38% |
| kelp | 87.5% | 96.47% |
| p2porg | 96.0% | 96.43% |
These are entity-level averages across hundreds of block proposals. A 94–96% head accuracy means roughly 1 in 18 to 1 in 25 validators is voting for the wrong head during that entity's slots — compared to roughly 1 in 200 for binance (0.07% timing game blocks, 99.44% accuracy) or solo stakers (1.1%, 99.16%).
The most striking data point is the split within the same operating organisations.
p2porg, running validators independently: 96% timing game blocks. p2porg_lido, running validators under the Lido node operator programme: 0% timing game. Same company, different configuration, wildly different behaviour.
Everstake standalone: 59% timing game. Everstake Lido: 0.6%.
This isn't an infrastructure story. p2porg's independent validators aren't slow because their hardware is slow — if hardware were the bottleneck, their Lido validators would be slow too. The split tells you the timing delay is a deliberate configuration choice: a MEV-Boost bid wait time, a relay cutoff, something adjustable that someone has adjusted differently for the two validator sets.
To double-check that the pattern is structural rather than a statistical artefact, here are the daily timing game rates for the top offenders:
-- Daily consistency check
SELECT toDate(slot_start_date_time) as day, entity,
countIf(first_seen_ms >= 3000) / count() * 100 as pct_late
-- (Python merge: timing × entity × day)
| Day | p2porg | everstake | kelp | binance | solo_stakers |
|---|---|---|---|---|---|
| Feb 17 | 100% | 94.6% | 84.6% | 0.0% | 0.5% |
| Feb 18 | 94.7% | 95.5% | 87.0% | 0.4% | 1.2% |
| Feb 19 | 97.9% | 74.8% | 95.7% | 0.0% | 1.2% |
| Feb 20 | 92.9% | 42.5% | 94.1% | 0.0% | 1.4% |
| Feb 21 | 95.6% | 36.9% | 100% | 0.0% | 0.5% |
| Feb 22 | 95.5% | 42.6% | 79.2% | 0.0% | 0.9% |
| Feb 23 | 96.4% | 37.8% | 75.9% | 0.2% | 1.6% |
p2porg is remarkably stable (92.9–100%, every day). Everstake fluctuates more, suggesting dynamic MEV settings that change with market conditions. Kelp started at 84.6% and remained very high. Binance and solo stakers are consistently near zero.
This matters because the attestation cost isn't theoretical. Every late block from these entities causes some fraction of the validator set to vote for the wrong head. Compounded across thousands of proposals, across months, this is a structural drag on consensus quality that comes from a small number of entities that have deliberately chosen aggressive MEV timing settings.
There's a reasonable counterargument: the timing game extracts more value, and the proposer capturing more MEV is presumably passing some of that to stakers. The data here doesn't resolve whether the MEV gain outweighs the network externality — that requires pricing the attestation degradation. What the data does establish is that the externality is real, entity-specific, and structurally driven by configuration choices that some operators make for their independent validators but not for their Lido-operated ones.
The Lido node operator programme, at least for these operators, appears to be enforcing something closer to on-time behaviour. Whether that's explicit policy, monitoring, or just different MEV configurations is unclear. But the gap is stark: same people, different programmes, consistently different outcomes.
Data: 7 days, 45,401 labelled slots, Feb 17–23 2026. Sources: libp2p_gossipsub_beacon_block (xatu) for block first-seen times; mainnet.fct_block_proposer_entity and mainnet.fct_attestation_correctness_canonical (xatu-cbt) for entity labels and head vote accuracy. Entities with fewer than 100 blocks in the window excluded. Block first-seen is MIN(propagation_slot_start_diff) — earliest time any EthPandaOps crawler observed the gossip message.