PeerDAS has been running on mainnet for 30 days, and column index predicts propagation speed
PeerDAS — EIP-7594's data availability sampling system — has been live on Ethereum mainnet for over 30 days. All 128 column subnets are active, and the data is arriving: 10,956 out of 10,958 slots in the last 48 hours had every single column propagate within 12 seconds. That's 99.98% completeness. The protocol is working.
But there's something nobody seems to have noticed: column index 0 arrives 156 milliseconds faster than column index 101. The correlation between column index and median propagation time is 0.82. And it's been this way, consistently, for seven consecutive days.
The data lives in libp2p_gossipsub_data_column_sidecar in Xatu — a table that records every time an EthPandaOps observation node sees a gossip message on a PeerDAS column subnet. Pulling 48 hours of mainnet data, filtered to propagation times between 100ms and 12,000ms:
SELECT
column_index,
count() as obs,
quantileExact(0.5)(propagation_slot_start_diff) as p50_ms,
quantileExact(0.95)(propagation_slot_start_diff) as p95_ms
FROM libp2p_gossipsub_data_column_sidecar
WHERE meta_network_name = 'mainnet'
AND slot_start_date_time >= now() - INTERVAL 48 HOUR
AND propagation_slot_start_diff BETWEEN 100 AND 12000
GROUP BY column_index
ORDER BY column_index
Column 0: 1544ms p50. Column 101: 1700ms p50. Column 127: 1642ms. The scatter plot makes the pattern unmistakable.
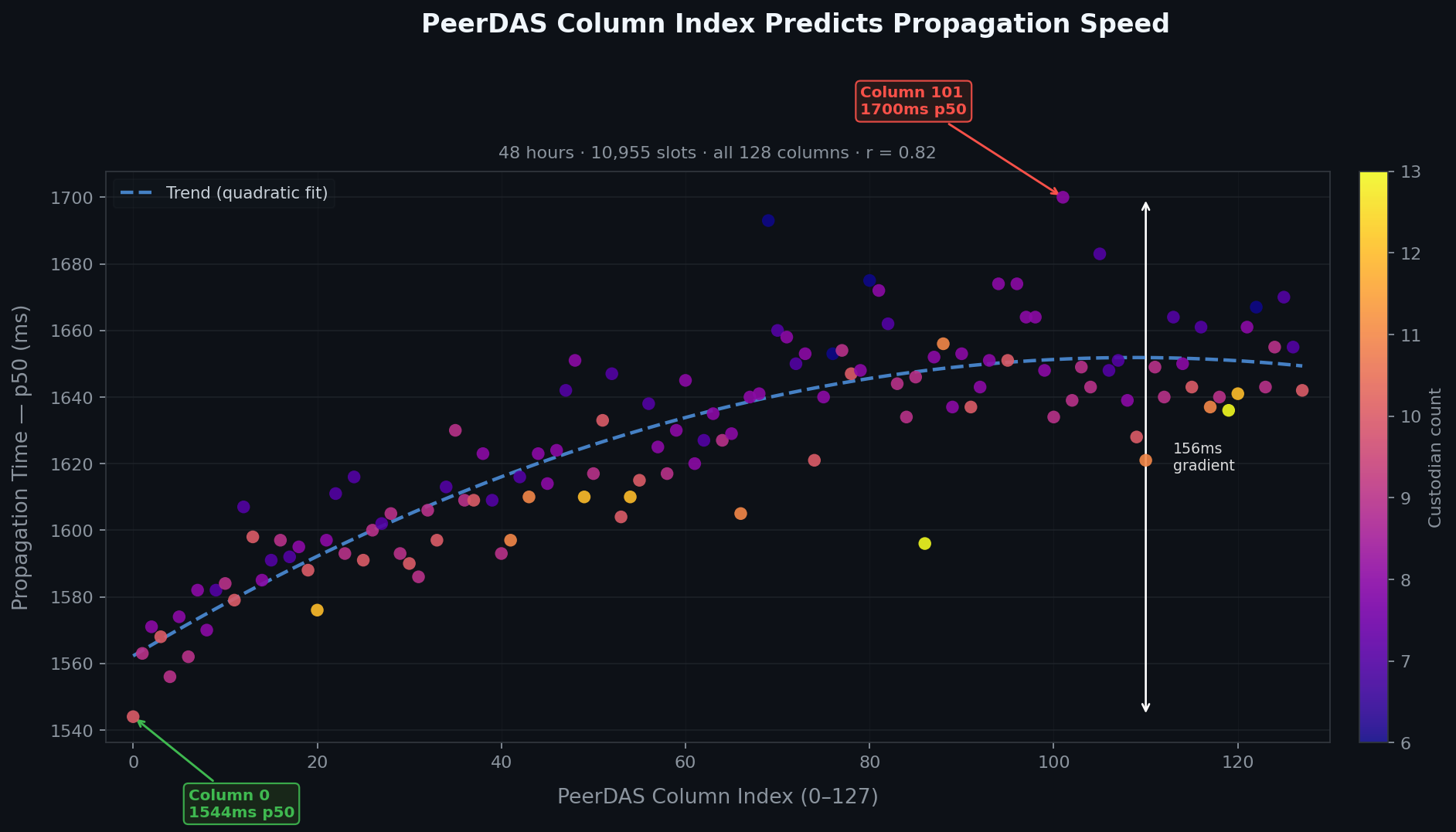
The blue dashed trend line follows a roughly logarithmic curve — steep improvement in the first 64 columns, then leveling off. Columns 96–127 are mostly clustered around 1640–1700ms; columns 0–31 cluster around 1540–1620ms. The dots are colored by custodian count (how many observation nodes are subscribed to that subnet) — more on that in a moment.
Before assuming this is noise, the same query broken into 32-column bands over 7 days:
SELECT
toDate(slot_start_date_time) as day,
intDiv(column_index, 32) * 32 as col_band,
quantileExact(0.5)(propagation_slot_start_diff) as p50_ms
FROM libp2p_gossipsub_data_column_sidecar
WHERE meta_network_name = 'mainnet'
AND slot_start_date_time >= now() - INTERVAL 7 DAY
AND propagation_slot_start_diff BETWEEN 100 AND 12000
GROUP BY day, col_band
ORDER BY day, col_band
Every single day, the same ordering holds: band 0–31 is fastest, then 32–63, then 64–95, then 96–127. The 7-day aggregate for each band: 1585ms, 1620ms, 1648ms, 1652ms. The gap is ~67ms and it does not close. This is structural, not random.
What drives it? There are two candidates.
The first is custodian count. The EthPandaOps observation network includes about 20 nodes that each custody 8 columns (the minimum per EIP-7594's custody requirement), plus 6 full nodes that subscribe to all 128. Whether a given column also has sharded nodes custodying it — and how many — varies. Columns with more observers have more redundant gossip paths:
SELECT
column_index,
count(DISTINCT meta_client_name) as total_custodians
FROM libp2p_gossipsub_data_column_sidecar
WHERE meta_network_name = 'mainnet'
AND slot_start_date_time >= now() - INTERVAL 6 HOUR
GROUP BY column_index
ORDER BY column_index
Custodian counts range from 6 to 13 per column. Columns with 6 custodians average 1672ms; columns with 13 custodians average 1616ms. The correlation between custodian count and p50 is −0.33 — real but weak.
The column_index correlation is 0.82. So custodian count accounts for part of the effect but not most of it. Something about lower-indexed column subnets makes them intrinsically faster, beyond just the number of nodes watching them.
The most plausible explanation is gossip mesh maturity. In libp2p gossipsub, each topic maintains its own mesh of D peers. When a node joins and subscribes to 128 column topics in ascending order (0, 1, 2, ..., 127), the mesh for topic 0 begins forming first. Over time — across restarts, peer churn, and rebalancing cycles — lower-indexed topic meshes have accumulated more connection-time and are more stable. When a new column sidecar is published, it traverses a denser, more established fanout tree on subnet 0 than on subnet 96.
The smoking gun: the fastest-ever propagation time for each column is essentially identical regardless of index. Column 0's fastest observed arrival was 138ms; column 127's was 134ms. The absolute floor — the direct-custody hot path — is equally fast for all columns. The gradient only appears in the median. That means the typical gossip relay path is slower for high-index columns, while the best-case path (direct peering) is uniform. Mesh maturity explains this: the direct path works regardless of mesh quality; the multi-hop gossip path depends on how well-connected the mesh is.
The practical consequence is mild but real. PeerDAS samplers are supposed to query a random subset of columns to verify data availability. If you happen to sample column 4 and column 101, you'll get an answer from column 4 about 150ms sooner. That's a meaningful fraction of a typical sampling window. It won't break DA verification — all 128 columns are arriving before the slot closes — but it creates a subtle asymmetry in sampling latency that the spec doesn't account for.
Whether this is a transient bootstrapping artifact or a stable feature of the mainnet PeerDAS gossip network is something worth watching. If the gradient shrinks over months as the mesh matures uniformly, it's temporary. If it persists, it's a permanent property of how libp2p gossipsub behaves at 128-topic scale.
Data: 48 hours (10,958 slots) for primary analysis; 7 days for trend verification. Feb 21–23 2026. Source: Xatu libp2p_gossipsub_data_column_sidecar, mainnet. Propagation time is relative to slot start (propagation_slot_start_diff), filtered 100–12,000ms to exclude late-processing outliers. Observation network: ~6 full-subscriber nodes + ~20 sharded 8-column nodes. Custodian counts reflect distinct EthPandaOps clients, not the broader mainnet custody network.